

Ile razy musiałeś „wyciągać” lub rozdzielać dynamicznie imiona i nazwiska i wyświetlać je w osobnej tabeli? A może tytuły naukowe? Prefixy numerów telefonów, aby połączyć je z odpowiednim krajem? Nawet jeśli nie miałeś takiej potrzeby to rozwiązanie tego nie jest bułką z masłem szczególnie gdy ilość znaków lub słów się zmienia z każdą komórką a i separatory się zmieniają. Narzędzie takie jak Tekst Jako Kolumny niestety nie działa dynamicznie tylko statycznie i za każdym razem trzeba czynność powtarzać. Dodatkowo trzeba by było użyć go tyle razy ile jest wariantów w danych źródłowych. I jeszcze sortować… Eh!
Aby obsłużyć te problemy można użyć zestawu zagnieżdżonych funkcji tekstowych wraz z funkcjami warunkowymi, gdy ilość słów się różni. Formuła na pewno będzie działała poprawnie, jednak utworzenie takiej wymaga doświadczenia, czasu i testów. Takiego potworka zobaczysz w późniejszym przykładzie. Na pewno nie będzie ona łatwo czytelna i na pewno będzie bardzo długa.
Microsoft wraz z wersją 365 wyszedł naprzeciw naszym cierpieniom i wprowadził nowe funkcje TEKST.PRZED i TEKST.PO, które eliminują potrzebę zagnieżdżania ze sobą funkcji w tradycyjny sposób.
Zobacz jakie to proste! 😊

Funkcje TEKST.PRZED oraz TEKST.PO zwracają tekst (zazwyczaj z odwołania/adresu) przed lub po tzw. ogranicznikiem, separatorem lub dowolnym innym znakiem. Separator w rzeczywistości nie musi być spacją, średnikiem czy myślnikiem etc. Obie funkcje są takim odbiciem lustrzanym wobec siebie tak samo jak funkcje LEWY i PRAWY. W zasadzie właśnie te ostatnie mają być zastąpione w większości przypadków przez ich omawianych tu następców.
Jeśli posiadasz subskrypcję Microsoft 365 to możesz się cieszyć z najnowszych funkcjonalności i korzystać z tych funkcji. Technicznie znajdziesz je w bibliotece funkcji tekstowych na karcie Formuły.
TEKST.PRZED i TEKST.PO zostały wraz z 12 innymi ogłoszone na początku 2022 roku, więc z historycznego punktu widzenia są to nowe dzieci Excela. Dziękujemy Ci Joe McDaid i prosimy o więcej!
Pssst… 😉 narzędzia, które masz dostępne od lat, a potrafią to samo są wbudowane w POWER QUERY :). Zapraszamy do nas na kurs POWER QUERY!
Jedna i druga funkcja mają po 7 takich samych argumentów, a składnia jest następująca:
=TEKST.PRZED(text; delimiter; [instance_num]; [match_mode]; [match_end]; [if_not_found])
Zwróć uwagę, że na czas tworzenia tego artykułu nie ma polskiego tłumaczenia argumentów w oknie dialogowym funkcji, natomiast w pasku formuły podpowiedzi i listy rozwijane już są po polsku. Niemniej jednak bez obaw, tajemnicze nazwy za moment będą jasne i zrozumiałe.
text Pierwszy wymagany argument jest to tekst, z którego chcesz wyodrębnić jego część. Zwykle jest to odwołanie, inaczej użycie tej funkcji miało by dość wątpliwy sens.
delimiter Inaczej ogranicznik, separator. Może to być zwykły znak mogący wystąpić w tekście. Oznacza punkt, który jest granicą, do której lub od której będzie zwracany tekst wynikowy. Jest to drugi i ostatni argument wymagany, który musisz podać w tych funkcjach.
instance_num Jest to liczba, w której podajesz od którego wystąpienia ogranicznika chcesz zwracać tekst. A może od drugiego wystąpienia? Wprowadź zatem 2. Domyślnie jest od samego początku, czyli od 1.
To z tym argumentem możesz zdziałać cuda i dynamicznie manipulować wartościami. Dodatkowo, wpisanie -1 (minus jeden) odwróci poszukiwanie (pierwszego) separatora i wystartuje z przeciwnego kierunku, a mówiąc precyzyjnie zwróci tekst przed ostatnim separatorem. Analogicznie -2 dla drugiego przed-przedostatniego. Np. z „Ala ma kota” zwróci „Ala ma” lub „Ala” dla -2.
match_mode Typ dopasowania, gdybyśmy chcieli tłumaczyć na język polski. Ustawiamy 0 lub 1 gdy chcemy szukać separatora w postaci litery z rozróżnieniem na wielkie i małe litery. Tu należy uważać, ponieważ domyślnie jest wrażliwy na wielkość liter, czyli 0. Pozbywamy funkcji tej wrażliwości zmieniając argument na 1.
Używałeś kiedyś kombinacji LEWY i ZNAJDŹ? Właśnie ZNAJDŹ jest domyślnie wrażliwe na wielkość liter (Case sensitive). SZUKAJ.TEKST natomiast wrażliwy nie jest. O wiele łatwiej jest wpisać 0 lub 1 niż zagnieżdżać kolejne funkcje, prawda?
match_end Ten argument można przetłumaczyć dla wygody jako dopasuj końcówkę. Oznacza to, że na końcu tekstu zostanie dodany „niewidzialny” separator. Zero (0) nie wstawia go, a jeden (1) wstawia. W praktyce, gdy separator nie zostanie znaleziony to zwrócony zostanie cały tekst, inaczej będzie błąd #N/D.
Gdybyś chciał to osiągnąć w tradycyjny sposób, należy całą zagnieżdżoną formułę (LEWY/ZNAJDŹ) użyć ponownie w JEŻELI.BŁĄD, ponieważ wynikiem będzie #ARG!.
if_not_found Ostatni opcjonalny argument pozwala nam wyświetlić tekst lub odwołanie w przypadku nie znalezionego fragmentu, a dokładniej mówiąc gdy szukany separator nie istnieje w tekście. Do naszego monstrum z poprzedniego argumentu, należy dodać JEŻELI.ND na sam początek, aby uzyskać taki sam efekt w tradycyjnym rozwiązaniu z przed pakietu 365.
Aby wyodrębnić tekst przed ogranicznikiem lub po wystarczy użyć dwóch wymaganych argumentów text i delimiter. Załóżmy, że chcemy dynamicznie rozdzielać imiona od nazwisk
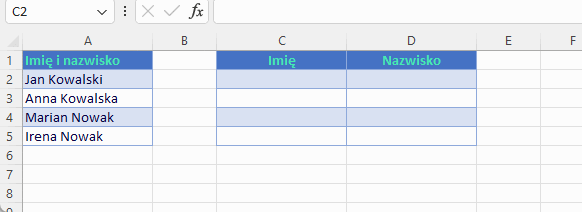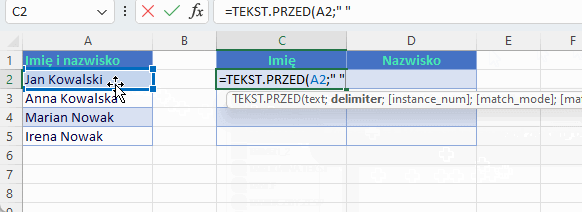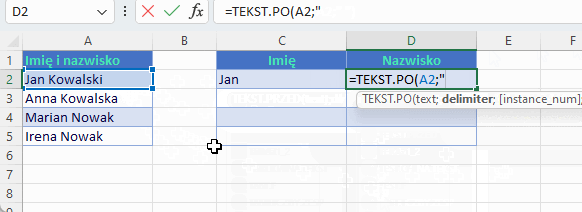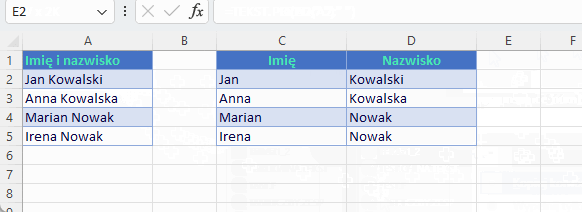
W jaki sposób wyodrębniamy imię i nazwisko tradycyjną metodą? A tak jak poniżej. Widać różnicę?
Imię
=LEWY(A2; ZNAJDŹ(” „;A2)-1)
Nazwisko
=PRAWY(A2;DŁ(A2)-ZNAJDŹ(” „;A2))
Jak już wcześniej zobaczyłeś/aś, aby włączyć lub wyłączyć sprawdzanie wielkości liter używasz argumentu match_mode. Domyślnie funkcje, które omawiamy mają włączoną opcję uwzględniania wielkości liter. Aby to wyłączyć należy czwarty argument podać w postaci liczby 1. Zobacz, że zlepek danych w tabelce ma wyraz Country, który w całości jest naszym separatorem. Raz występuje z wielkiej litery a raz z małej. Żaden problem dla nas!
Jeśli zdarzy się kiedyś taka potrzeba to poniżej jest przykład użycia:
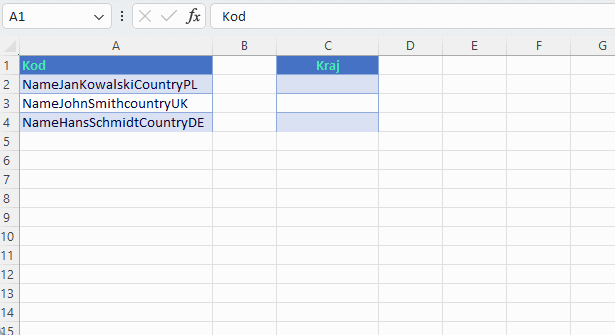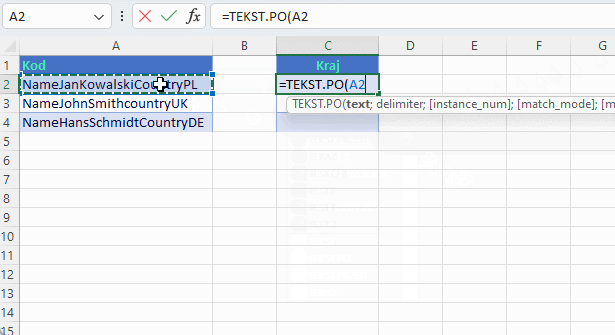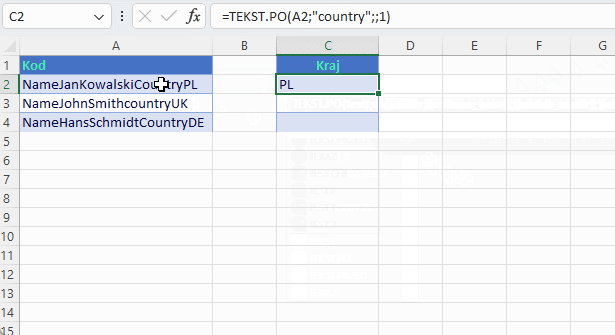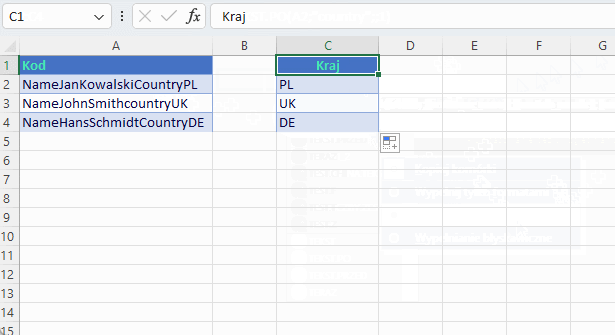
Jak wygląda wersja tradycyjna w tym przykładzie?
=PRAWY(A2;DŁ(A2)-SZUKAJ.TEKST(„country”;A2)-6)
Argument służący do wyboru, od którego separatora chcemy zacząć poszukiwanie to instance_number – pierwszy opcjonalny. W przykładzie mamy zrzut z systemu transakcyjnego w formie ciągu tekstowego, z którego potrzebujemy do dalszych analiz wyodrębnić datę, którą Excel będzie wstanie rozpoznać. Póki co jest tekstem połączonym z innym ciągiem i występuje po 3 separatorze myślnika. A myślników jest 5. Plik tekstowe csv mogą być długim ciągiem oddzielonym przecinkami lub średnikami.
=TEKST.PRZED(text,delimiter,[instance_num], [match_mode], [match_end], [if_not_found])
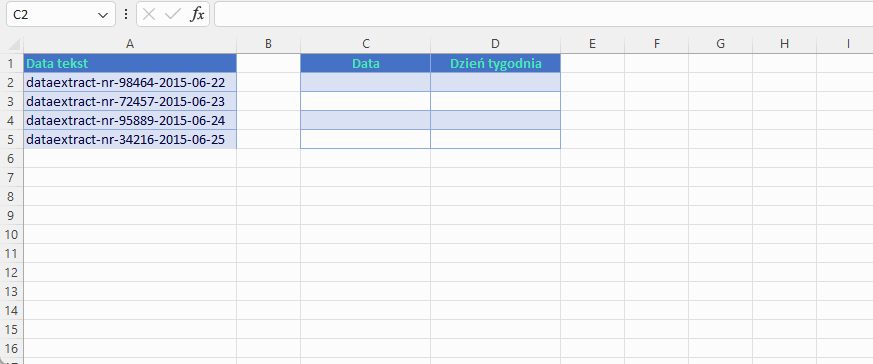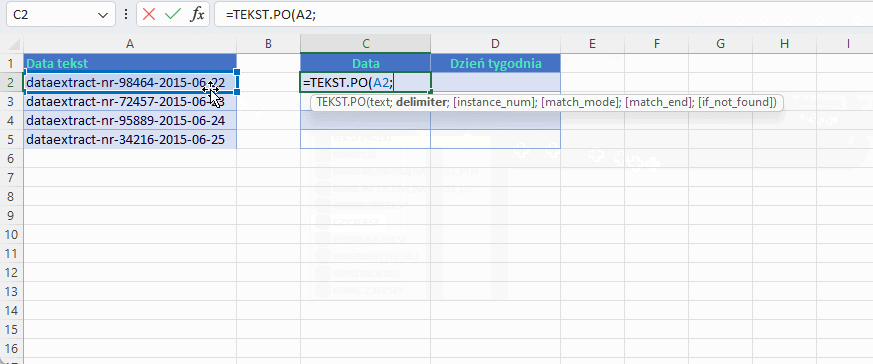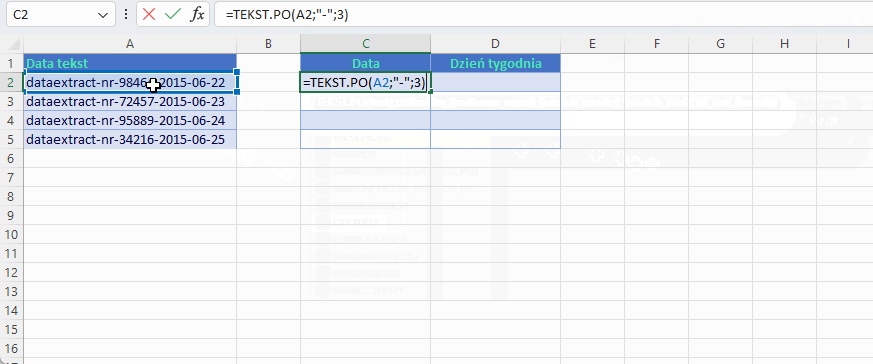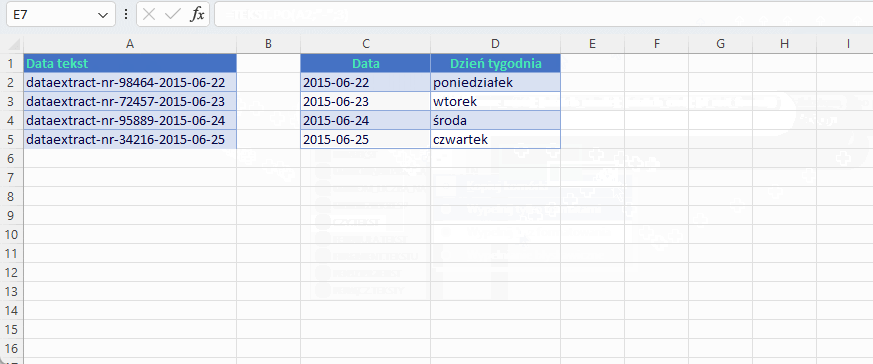
W związku z tym, że w przykładzie posługuję się wyodrębnianiem daty, która ma stałą długość dziesięciu znaków to tradycyjna metoda za pomocą funkcji PRAWY sprawdzi się nawet lepiej a przynajmniej o jeden argument krócej. Jednak nie zawsze może być to data i/lub stała ilość znaków.
=TEKST.PRZED(text,delimiter,[instance_num], [match_mode], [match_end], [if_not_found])
Argument match_end umożliwia nam wybranie dwóch wariantów. W przypadku gdy szukany separator w tekście do podzielenia nie występuje (w argumencie text) to możemy otrzymać wynik #N/D lub wyświetlić cały tekst. Obie wersje w zależności od naszego projektu mogą być bardzo przydatne. Takie #N/D możemy wyświetlić i sformatować warunkowo narzędziem formatowanie warunkowe i/lub wykorzystać ostatni argument opcjonalny funkcji [if_not_found].
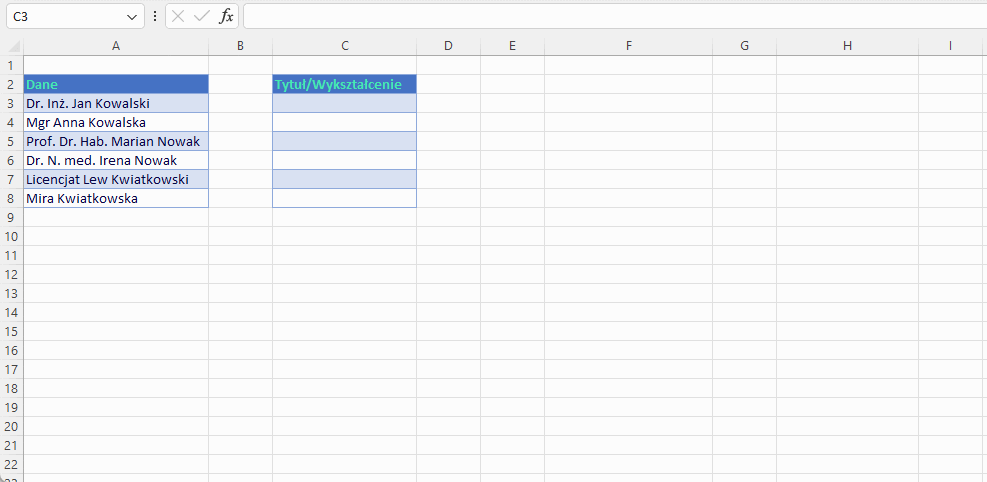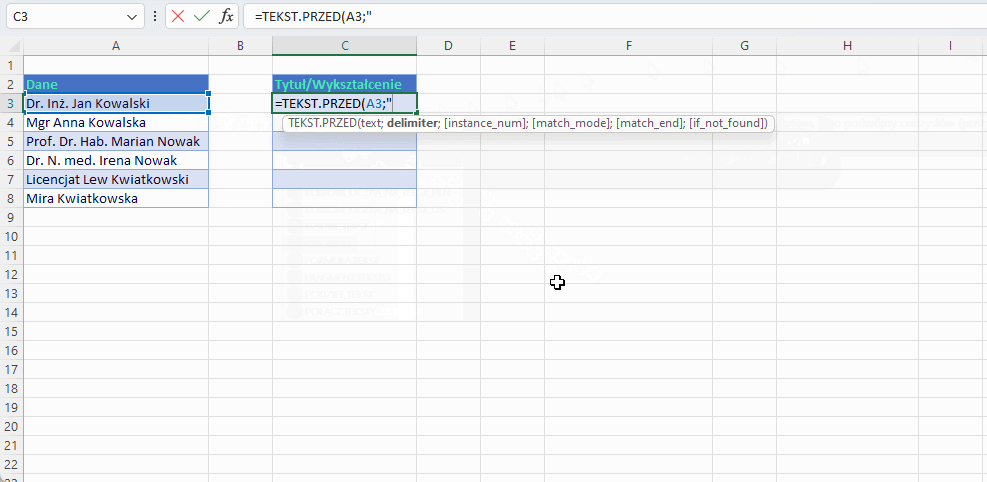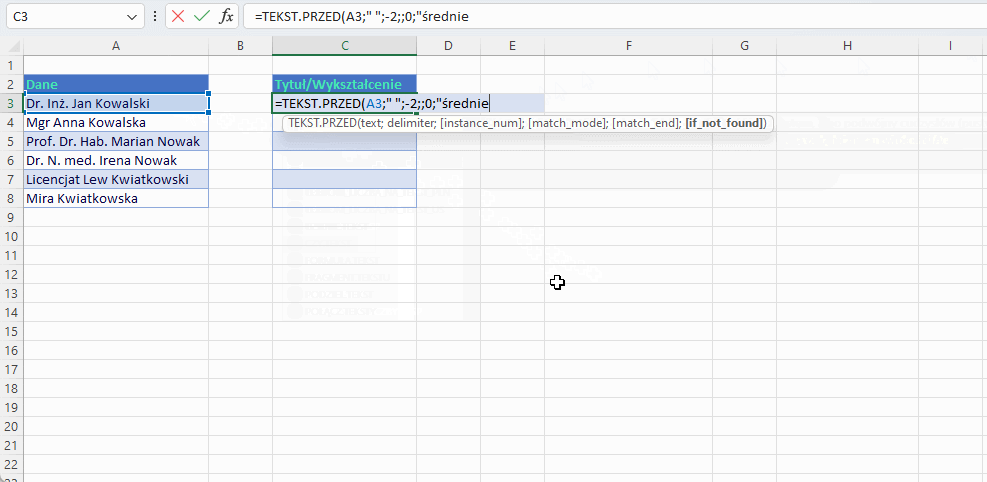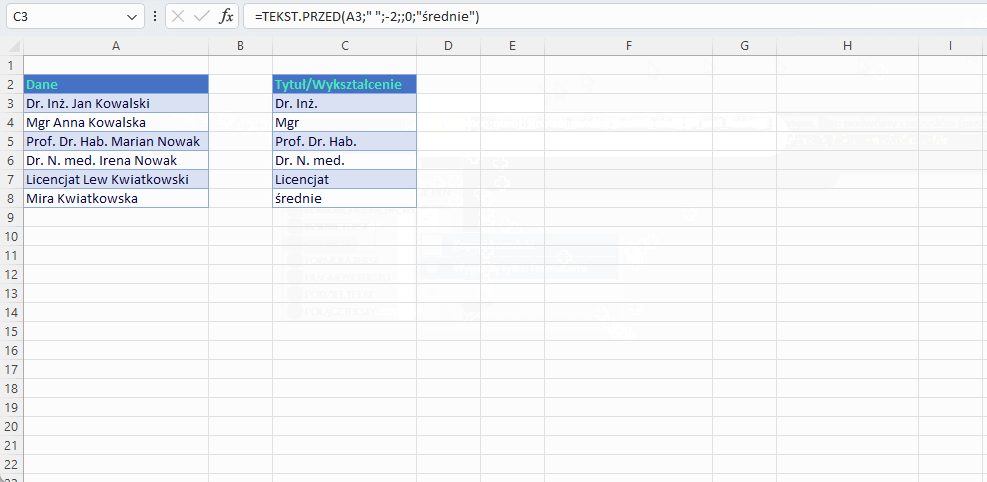
W poniższym przykładzie naszym zadaniem jest wyświetlenie pełnych tytułów naukowych, które są co najmniej „doktorem”.
Naszym ogranicznikiem, przed którym chcemy wyodrębnić tekst jest ostatnia kropka. Czasem kropek w tekście jest 3, czasem 2 a czasem zero gdy tytuł to magister lub wcale nie ma tytułu. W takim przypadku funkcja ułatwia nam to zadanie i zaczniemy poszukiwania od końca tekstu. Ustawiamy argument instance_number na -1. Oznacza to dosłownie znajdź pierwszy od prawej. Argument związany z wielkością liter możemy pominąć i zostawić domyślne 0 (case sensitive). Kropka jako separator tego nie rozróżnia. Ostatecznie nasz zwrócony tekst jest pozbawiony separatora kropki, z przed którego wyciągnęliśmy ciąg znaków, zatem dołączamy znakiem konkatenacji (ampersandem) brakujące ogniwo.
=TEKST.PRZED(A3;”.”;-1;;0) &”.”
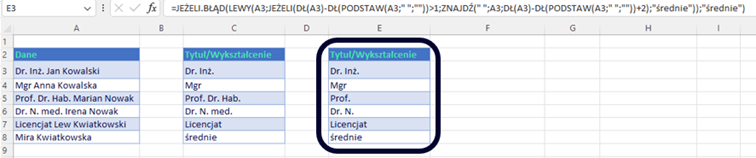
Gdyby zdarzyło się, że tytułów jest więcej i chcielibyśmy wyświetlić je wszystkie wtedy musimy lekko zmodyfikować logikę naszej funkcji. Zakładamy, że osoba bez żadnego tytułu posiada wykształcenie średnie. Zwróć uwagę że Mira Kwiatkowska nie ma dwóch spacji, a szukamy drugiej spacji od prawej strony, która wskazuje nam, że dalej powinien być tytuł naukowy.
Aby uzyskać ten sam efekt możemy użyć tradycyjnej metody, którą możesz sobie przeanalizować poniżej… jeśli masz odpowiednią motywację 😊 .
Nowe rozwiązanie:
=TEKST.PRZED(A3;” „;-2;;0;”średnie”)
Stare rozwiązanie (propozycja):
=JEŻELI.BŁĄD(LEWY(A3;JEŻELI(DŁ(A3)-DŁ(PODSTAW(A3;” „;””))>1;ZNAJDŹ(” „;A3;DŁ(A3)-DŁ(PODSTAW(A3;” „;””))+2);”średnie”));”średnie”)
Obie funkcje mogą zwrócić 2 rodzaje błędów:
Uwaga! To są podstawowe błędy przewidziane dla tej funkcji przez Microsoft, ale inwencja twórcza użytkowników Excela nie zna granic, dlatego też jest pewne, że takie błędy jak #NAZWA?, #WARTOŚĆ! czy #DZIEL/0! wystąpią prędzej czy później. Tu nasuwa się zasadnicze pytanie jak na to zaradzić? Odpowiedź jest prosta! 😊 Zapraszamy na nasze kursy Excel!
Znaki wieloznaczne takie jak „*” (dowolny ciąg znaków) i „?” (dowolny jeden znak) nie są obsługiwane przez te funkcje. To oznacza, że przy takim tekście do podziału jak „ala ma kota”, nie możemy jako separatora użyć np. „??”, który miałby znaleźć dowolny (pierwszy) ciąg dwóch znaków i zwrócić „ala „.
Oczywiście są możliwości na obejście tego problemu, ale nie o to chodzi, aby sobie sprawy komplikować tylko ułatwiać.
W Excelu generalnie nie ma rzeczy, których się nie da zrobić!

